Mohamed Louadi: De la préservation du patrimoine culturel de l’Afrique à l’ère de l’Intelligence Artificielle

.jpg) Par Mohamed Louadi, PhD - Professeur des universités à l’ISG, Université de Tunis. En 2017 le numéro spécial du magazine britannique The Economist annonçait en couverture que la ressource la plus précieuse était désormais les données. Cela faisait écho à l’expression «data is the new oil», formulée en 2006 par Clive Humby, spécialiste en sciences des données.
Par Mohamed Louadi, PhD - Professeur des universités à l’ISG, Université de Tunis. En 2017 le numéro spécial du magazine britannique The Economist annonçait en couverture que la ressource la plus précieuse était désormais les données. Cela faisait écho à l’expression «data is the new oil», formulée en 2006 par Clive Humby, spécialiste en sciences des données.
En 2018 James Bridle précisa que les données ne sont pas le nouveau pétrole mais la nouvelle énergie nucléaire en cela qu’elles sont illimitées et dans leur capacité de nuire(1).
De fait, depuis les années 1960, les termes suivants se sont succédés à un rythme effréné: data base, datawarehouse, databank, datamining, datamart, data store, big data, data lake, dataset, tous des termes à consonnance anglo-saxonne avec parfois des tentatives plus ou moins heureuses de traductions dans d’autres langues.
Mais depuis la nuit des temps, les données ont été à la base de la communication et de la transmission des connaissances entre les humains, qui évoluèrent en quatre étapes, l’oral, l’écrit, l’imprimé et le numérique.
Les étapes de la transmission des connaissances
L’oral
Au nord de Vancouver vit une tribu pour qui chaque fois qu’on tue une personne on tue une histoire. Cette croyance est partagée par moult cultures et civilisations pour qui le passé était transmis de bouche à oreille, autour d’un feu de bivouac ou au fond d’une grotte lorsque nos ancêtres cherchaient refuge loin des intempéries. Ces histoires étaient mémorisées et transmises d’une génération à une autre.
Aujourd’hui encore, la tradition orale continue à être un aspect fondamental de la culture traditionnelle non seulement des Squamish mais de bien d’autres cultures. En 2010, la langue Squamish avait quasiment disparu puisqu’elle n’était plus parlée que par dix des 3,900 individus restants. Un jour prochain l’histoire de plus d’un millénaire de cette tribu, et d’autres, ne sera plus contée oralement, ni même dans sa langue d’origine, avec les pertes de sens et de subtilités que l’on devine.
Les langues, vecteur de transmission orale
Les langues disparaissent-elles?
Alors qu’il y a à peine 1000 ans il y avait près de 9000 langues parlées dans le monde, il n’en reste plus qu’entre 6500(2) et 7168, dont 2140 en Afrique. Les spécialistes prévoient qu’en 2050, il ne restera qu’environ 4500 langues, 3000 en 2100 et 100 au début du 23ème siècle(3). Si ce ne sont pas des langues qui disparaitront, ce seront les mots ou les tournures de phrase qui se perdront, souvent sans être remplacés, ou qui seront simplement regroupés(4) participant ainsi à un appauvrissement progressif des langues.
Alors que les histoires étaient transmises oralement grâce au langage, les humains d’avant avaient une mémoire impressionnante comparée à la nôtre. On raconte qu’à la simple lecture d’un poème, nos aïeux étaient capables de le restituer mot pour mot. Les troubadours tout autant que les poètes arabes rivalisaient entre eux et la mémoire était appréciée sinon adulée.
A un moment de l’histoire de l’humanité, l’écrit apparut, vraisemblance en Mésopotamie.
L’écrit
Mais on raconte que Socrate méprisait l’écriture parce qu’il pensait qu’elle encourageait la paresse et diminuait la mémoire. Il est notoire que ce raisonnement l’opposait à Platon qui, dans sa pièce Phèdre, dépeint Socrate comme déplorant le développement de l’écriture.
Diogène aussi considérait que l’écriture était inférieure à la parole qui permet une communication plus authentique et immédiate. Selon lui, l'écriture fige la pensée, elle permet aux individus de dissimuler leurs véritables pensées derrière des mots écrits et de manipuler la vérité. Paradoxalement, Diogène ne s’était pourtant pas privé d’avoir des écrits, mais aucun de ses textes ne lui survécut, certains parce que ce fut lui-même qui les brûla. Ce que nous savons aujourd’hui des écrits de Diogène nous est parvenu par fragments grâce à des témoignages oraux.
Ainsi nous nous sommes dessaisis d’énormes capacités mémorielles lorsque nous nous sommes mis à écrire (ou à dessiner) et, plus tard, à enregistrer.
Ainsi si les langues disparaissent, la mémoire humaine dépérit aussi.
L’humain a pris pour habitude de ne garder dans sa mémoire que ce qui n’est pas accessible ailleurs. Il se mit alors à décharger sa mémoire dans des appareils. C’est ainsi que nous avons oublié les numéros de téléphone de nos proches lorsque nous avons acheté des téléphones portatifs. Les systèmes GPS ont peut-être diminué notre capacité à lire des cartes et les correcteurs d’orthographe ou les calculatrices ont peut-être contribué à l’émergence d’une génération qui n’est plus rompue aux règles de l’orthographe, de la grammaire ou du calcul mental. Nous n’internalisons dans nos corps que ce qui ne peut être trouvé ailleurs. Bientôt les technologies hébergeront tout ce qui est supposé être dans nos têtes: mémoire, raisonnement, imagination, etc.
Puis vint l’imprimé.
L’imprimé
L’imprimerie fut inventée par les Chinois et vulgarisée un millier d’années plus tard par Johann Gutenberg. Elle nous permit d’étendre la disponibilité de l’écrit en le dupliquant plus rapidement que la recopie des scribes. Au 10ème siècle, avec 426 titres la bibliothèque suisse de Saint-Gall était la plus grande du monde chrétien d’alors. Chacun de ces ouvrages était une copie unique accessible seulement à ceux qui pouvaient se payer le déplacement. En raison de l’indisponibilité immédiate des écrits, les gens lettrés étaient contraints d’apprendre par cœur les œuvres de ceux qui les ont précédés (Homère, Platon, etc.); chose dont ils s’acquittaient encore avec aisance.
Très vite après l’avènement de l’imprimerie nous avons alors commencé non seulement à remplir les bibliothèques de livres mais à multiplier le nombre des bibliothèques. On raconte qu’avant la machine de Gutenberg, il y avait à peine 30.000 livres dans toute l’Europe. Cinquante ans plus tard il y en avait dix millions imprimés dans 236 villes d’Europe(5). Au 10ème siècle, dans la seule ville de Cordoue il y avait 70 bibliothèques publiques.
Si comme l’avance Farrukh Saleem celui qui détient la plus grande bibliothèque règne sur le monde(6), plusieurs peuples étaient défavorisés d’entrée de jeu.
Aujourd’hui, c’est la Bibliothèque du Congrès américain qui, avec 170 millions d’ouvrages, détient le plus grand nombre de volumes.
La précarité de l’oral, de l’écrit et de l’imprimé
Sans doute un gage de fierté pour ceux qui les possèdent, les bibliothèques se sont avérées très vulnérables. De célèbres bibliothèques, dont celle d'Alexandrie (Egypte), de Nalanda (Inde), de Celsus (Italie), ou de Bagdad, périrent dans les flammes, avec les pertes que l’on sait. Si ce ne sont pas les bibliothèques ce sont des milliers de livres qui furent allègrement brûlés dans des autodafés tristement célèbres(7).
Ainsi la survie des connaissances humaines accumulées était précaire tant que ces dernières étaient stockées sur des supports physiques comme le papier ou le papyrus.
Tout numériser
En 2004 Google avait décidé de numériser et de diffuser sur Internet des millions de volumes provenant de quatre bibliothèques américaines (Harvard, Stanford, Michigan et la bibliothèque publique de New York) et d’une université britannique (Oxford). Evalué à 150 millions de dollars à l’époque, le projet concernait 15 millions de volumes. Cinquante millions de volumes devaient être mis en ligne avant 2015. Le projet donnait suite à un autre projet, le projet Gutenberg, entamé en 1971 et qui avait le même objectif: numériser tous les livres en existence..jpg) Si ces projets avaient réussi, la bibliothèque résultante aurait invariablement été à dominance anglo-saxonne. Si déjà en 2011 430 langues étaient représentées dans Google Books, alors qu’on en dénombrait à peu près 7.000 dans le monde, près de la moitié des titres étaient en langue anglaise.
Si ces projets avaient réussi, la bibliothèque résultante aurait invariablement été à dominance anglo-saxonne. Si déjà en 2011 430 langues étaient représentées dans Google Books, alors qu’on en dénombrait à peu près 7.000 dans le monde, près de la moitié des titres étaient en langue anglaise.
La culture à travers les datasets
Cette hégémonie de la langue (et donc de la culture) subsiste aujourd’hui dans les datasets (ensembles de données) dont dépendent les grands modèles de langage (Large Language Models, ou LLM) tels que ChatGPT, GPT 4, Perplexity, Copilot ou Gemini. Un modèle comme ChatGPT était entraîné sur environ les deux tiers d’Internet, l’ensemble de Wikipédia, plus de 8 millions de documents (livres, articles, sites Web, conversations, etc.) et plus de 10 milliards de mots, tous issus d’une technologie dont 55% du contenu est en anglais.
Les données des pays développés sont surreprésentées dans les datasets d’entraînement avec lesquels avaient été développés ces LLM. Inversement, les données des pays en voie de développement sont sous-représentées; une partie très minime provient de l’Afrique par exemple.
Selon le rapport sur la santé Internet 2022 de Mozilla(8), de 2015 à 2020, concernant l’Afrique, seuls les datasets de l’Égypte avaient été utilisés dans les modèles d’apprentissage automatique. Ainsi, les Africains particulièrement ne jouissent pas de leurs cultures et sont maintenus dans une position de consommateurs des données des autres et des données des autres sur leurs propres cultures.
Ils se voient pour ainsi dire à travers les prismes des autres.
La précarité du numérique
Malheureusement, ce ne sont pas uniquement le papier et le papyrus qui sont susceptibles de dégradation. Le numérique apporte avec lui son cortège de nouveaux dangers tels que les pannes de disques durs, les virus informatiques, et les mauvaises manipulations humaines.
En 1986 l’incident de BBC Domesday avait marqué les imaginations et était devenu un exemple classique des dangers auxquels notre patrimoine numérique est exposé. A l’occasion du 900ème anniversaire du livre d’archives original datant de 1086, le Domesday Book, la BBC avait déboursé 2,5 millions de livres sterling pour en créer une version multimédia tenant sur deux disques laser. Ces disques contenaient désormais des archives concernant un million de personnes. Ils contenaient également 50.000 photos, 3.000 datasets, l’équivalent de 60 minutes d’images animées, 25.000 cartes et 250.000 noms d’endroits(9). Au fil des années les disques étaient devenus de moins en moins lisibles par des ordinateurs qui devenaient de plus en plus sophistiqués. Le problème fut plus tard résolu et les images, vidéos et autres données purent enfin être revisualisées. Cela ne se fit pas sans grande difficulté.
Ironiquement, l’ouvrage original était encore intact après 900 ans alors que les disques informatiques ne survécurent même pas quinze années.
En 1995, le gouvernement américain avait failli perdre une grande partie des données du recensement national en raison de l’obsolescence de sa technologie de récupération de données.
En 1996, en 2001 et en 2002 l’Internet même avait à plusieurs reprises frôlé la catastrophe.
Le 3 mars 2024 une grande panne de l’Internet interrompit plusieurs réseaux sociaux, particulièrement dans des pays comme l’Inde, le Pakistan et une partie de l’Afrique de l’Est. Sur le réseau des réseaux, la plupart du trafic de données est tributaire, dans une très large mesure, de câbles sous-marins qui sont susceptibles d’être endommagés par les ancres des navires, surtout dans une région aussi fréquentée que la mer Rouge où il y a plus de 15 câbles sous-marins. Ce jour- là, quatre de ces câbles furent endommagés en même temps.
Les technologies du numérique ne sont donc pas plus invulnérables que la mémoire humaine ou le papier.
En octobre 1991, la Tunisie se connecta à l’Internet, suivie, en novembre par l’Afrique du Sud. Les autres pays africains se connectèrent un à un jusqu’en novembre 2000, date à laquelle l’Érythrée ferma la marche.
L’Afrique?
L’Africain jouit moins des avantages d’être connecté au reste du monde qu’il n’en subit les inconvénients. Au plan culturel, le jeune Africain d’aujourd’hui risque d’en savoir davantage sur l’Empire britannique que sur l’Empire du Ghana. Il a plus de chances d’avoir entendu parler de Napoléon Bonaparte que de Soundiata Keita, le roi fondateur du grand empire du Mali. Il aura certainement entendu parler d’Elon Musk comme l’homme le plus riche de la planète plutôt mais pas de Mansa Musa, roi du Mali en 1312 et probablement l’homme le plus riche ayant jamais vécu. Et s’il a entendu parler de Léopold Cedar Senghor ou de Félix Houphouët-Boigny ce sera sûrement grâce aux médias occidentaux. A travers leur prisme.
La culture du numérique
Très malheureusement l’Afrique n’a encore guère de culture des données. Globalement, l’Afrique a la capacité statistique la plus faible. En effet, la capacité statistique a, au cours des quinze dernières années, diminué plus en Afrique que dans toute autre région du monde.
Seule la moitié des pays africains ont réalisé plus de deux enquêtes auprès des ménages comparables au cours des dix dernières années et seulement 29% ont publié des enquêtes auprès des ménages avec des données sur l’éducation depuis 2005.
Certes le contenu numérique africain existe déjà car des datasets africains existent bel et bien. Il existe même des LLM africains tels que, par exemple, Kainene vos Savant, Foondamate et MobileGPT.
Mais l’Afrique continue à ne contribuer que très marginalement à l’accumulation mondiale des données. Selon IDC(10), les contributions de chaque région à la création de données mondiales en 2023 était de 37,4% pour l’Amérique du Nord, 32,1% pour l’Asie-Pacifique, 19,3% pour l’Europe, 6,8% pour le Moyen-Orient et l’Afrique et 4,4% pour l’Amérique latine et les Caraïbes. La contribution de l’Afrique subsaharienne seule est estimée à 1,5%. Alors que la contribution de l’Europe à l’enregistrement de domaines Web était de 40,4 %, celle de l’Afrique subsaharienne était de 0,7 % (voir la figure 1). L’Afrique subsaharienne n’a contribué que 1,06% du total mondial des publications dans les revues d’IA alors que l’Asie de l’Est et l’Amérique du Nord y sont pour 42,87% et 22,70% respectivement.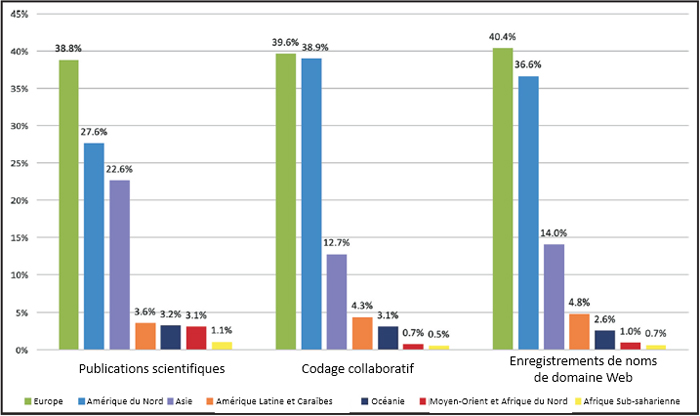 Figure 1. La comparaison de la création de contenu entre les continents. L’Afrique est constamment à la traîne des autres continents avec des pourcentages aussi bas que 0,5 %(11).
Figure 1. La comparaison de la création de contenu entre les continents. L’Afrique est constamment à la traîne des autres continents avec des pourcentages aussi bas que 0,5 %(11).
Si l’Afrique (1,3 milliard d’habitants) compte plus d’Internautes que l’Amérique du Nord (328 millions d’habitants)(12) elle dispose malheureusement d’à peine autant de centres de données (datacenters) que la Suisse (8,8 millions d’habitants). En 2023, les Etats-Unis comptaient 5.375 centres de données (2.670 en 2021). L’Allemagne, seconde dans le classement, en comptait 522. En 16ème position apparaissait la Suisse avec 120 centres de données(13).
Souvent même les propres données de l’Afrique sont stockées hors du continent.
Le commentaire de Farrukh Saleem à l’effet que c’est celui qui détient la plus grande bibliothèque qui règne sur le monde s’applique-t-il aussi aux centres de données ou de datasets?
La figure 2 ne suggère nullement que des datasets ou des modèles d’apprentissage automatique ne sont pas développés dans le reste du monde. Ils le sont. En général, un bon nombre des datasets les plus populaires sont constitués de contenus extraits d’Internet, qui, rappelons-le, reflète massivement des mots et des images qui biaisent l’anglais, l’américain, le blanc et le regard masculin(14); les modèles d’apprentissage automatique et les datasets reflètent à la fois les préjugés de leurs créateurs et les dynamiques de pouvoir profondément enracinées dans les sociétés.
Plusieurs peuples sont défavorisés d’entrée de jeu.
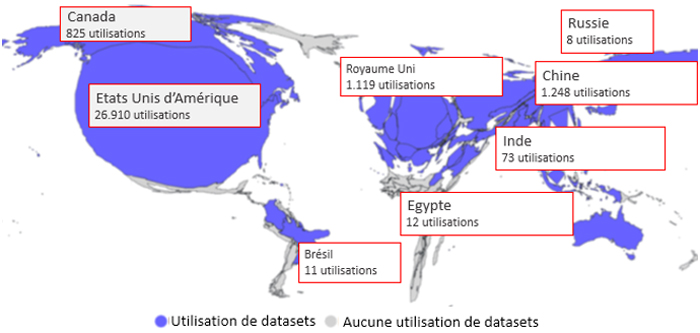 Figure 2. Comment les données voient le monde.
Figure 2. Comment les données voient le monde.
Les pays sont déformés en fonction de la fréquence d’utilisation des données dans les datasets. L’utilisation des données aux États-Unis représente le plus grand nombre d’utilisations (Graphique emprunté et traduit de Internet Health Report).
Le faible poids de l’Afrique en termes de données
Alors qu’en 2016 chaque Internaute dans le monde contribuait à l’Internet une moyenne de 1,7 mégaoctet par seconde, des gouvernements africains se sont mis à imposer des taxes sur la création de contenu numérique allant jusqu’à 15%(15). De telles mesures ne sont pas exactement propices au développement d’une culture de création de données. Cela voudra peut-être dire que la production de contenu africain coûtera plus cher que la consommation de contenu non-africain puisque le coût de téléchargement d'un gigaoctet varie entre 2% et 16% du revenu mensuel. Au Malawi, par exemple, un gigaoctet coûte en moyenne 27,41 dollars sur le mobile. Les coûts au Benin et au Tchad ne sont pas moins exorbitants(16).
Ces politiques peuvent être la conséquence (et la cause) du retard technologique dont souffre le continent. Dans l’Afrique subsaharienne où vivent 15% de la population mondiale, seulement 6% ont accès au haut débit. Pourtant les initiatives africaines ne manquent pas. Plusieurs pays ont lancé des plans, des programmes, ou des politiques de développement numérique. C’est le cas, entre autres du Sénégal, du Rwanda, du Kenya, du Maroc et de l’Afrique du Sud.
Cependant, l’Afrique doit faire face à un certain nombre de défis et surmonter un certain nombre d’obstacles pour exploiter pleinement le potentiel de l’économie des données.
Ces obstacles incluent la disponibilité croissante des appareils numériques et de connectivité, la croissance de l’économie numérique, l’adoption de technologies d’avant-garde comme l’IA et l’Internet des objets (IoT) ainsi que faire face à la demande croissante de prise de décision basée sur les données. Pour notre part, nous ne manquerons pas de souligner le défi représenté par le manque de compétences numériques. Un autre défi à relever est la nécessité de l’adoption très rapide d’une culture du numérique, plutôt que d’une culture numérique.
Conclusion
L’humanité a parcouru quatre étapes dans sa façon de transmettre les connaissances: l’oral, l’écrit, l’imprimé et le numérique. Alors que beaucoup de pays, en Afrique et ailleurs, en sont encore à l’étape orale, le basculement vers l’ère numérique semble inéluctable sinon très souhaitable. Rappelons que les outils numériques n’excluent nullement l’oral puisqu’ils sont en même temps multimédia, ce que ni l’écrit ni l’imprimé ne sont.
Les développements spectaculaires récents de l’IA nous ont démontré l’importance des données et des datasets.
Du fait même qu’elles sont issues de la culture de leurs créateurs les données d’entraînement utilisées dans l’apprentissage des IA, et particulièrement des LLM, colportent des biais favorisant cette culture et défavorisant les cultures qui ne sont pas porteuses de données, ou dénuées de données écrites, imprimées ou numériques.
Bon nombre de pays africains ont lancé des politiques d’investissement dans l’économie de l’immatériel dynamisant par cela des investissements dans le logiciel et la «numérisation». Alors qu’investir et encourager le développement, ou, du moins, l’utilisation des technologies numériques sont des politiques louables visant à promouvoir une culture numérique, la tâche d’instaurer une culture du numérique est bien plus ardue parce qu’elle vise à préserver et à perpétuer une culture. La technologie s’achète; pas la culture. Se restreindre à promouvoir le simple usage de technologies inventées ailleurs relèguera l’Afrique à un rôle de consommateur. La pierre angulaire du futur est la préservation d’une culture, et cela ne se fera que par le truchement des données.
L’Afrique est renommée pour sa richesse en matières premières. Il est temps qu’elle investisse dans les données, la matière première de base d’une économie du numérique dans laquelle l’Afrique est le continent qui hébergera le quart de l’humanité en 2050.
Mohamed Louadi
PhD - Professeur des universités à l’ISG, Université de Tunis
Lire aussi
Mohamed Louadi: L’intelligence artificielle, les grands modèles de langage et la nouvelle humanité
1) James Bridle (2018). Opinion: Data isn’t the new oil — it’s the new nuclear power, 17 juillet.
2) WorldData.info (n.d.). Geographical distribution of languages.
3) CIA Gov (2024). The World Factbook (2021 Archive).
4) Nous avons par exemple calculé que la locution «du coup» subitement surgie dans notre langage de tous les jours est venue remplacer jusqu’à 32 mots différents, dont «ainsi», «de ce fait», «donc», «en conséquence», «partant», «conséquemment», «subséquemment», «par voie de fait», «par voie de conséquence», etc. probablement jugés trop pédants pour notre époque.
5) Dominique Guellec (2004). Gutenberg revisité - Une analyse économique de l'invention de l'imprimerie, Revue d'économie politique 2004/2, Vol. 114, pp. 169-199.
6) Farrukh Saleem (2006). Who rules the world? Capital suggestion: Libraries, The News.
7) Comme ceux de l’Inquisition espagnole à Séville en juin 1481, des nazis en Allemagne en mai 1933, de la Révolution culturelle chinoise dans les années 1960 et occasionnellement des communistes.
8) Internet Health Report (2022). AI in Real Life, IRL Podcast | Season 6.
9) Robin McKie et Vanessa Thorpe (2002). Digital Domesday Book lasts 15 years not 1000, The Guardian, 3 mars.
10) IDC (2023). Worldwide Global DataSphere and Global StorageSphere Structured and Unstructured Data Forecast, 2023–2027, International Data Corp., June, Document number:# US50397723.
11) Sanna Ojanperä, Mark Graham, Ralph K. Straumann, Stefano De Sabbata, et Matthew Zook. (2017). Engagement in the knowledge economy: Regional patterns of content creation with a focus on sub-Saharan Africa. Information Technologies & International Development, Vol. 13, pp. 33–51.
12) 508,880 millions contre 444,060 selon les derniers chiffres de Statista (2023).
13) Cloudscene (2024). Switzerland, https://cloudscene.com/market/data-centers-in-switzerland/all, consulté le 24 février 2024.
14) Internet Health Report ( 2022). Op. Cit.
15) Ronald Agak (2024). Kenya: les créateurs de contenus contre une taxe sur leurs revenus, africanews du 25 février et Samira Njoya (2023). Kenya: la taxe de 15% imposée aux créateurs de contenu est entrée en vigueur, We Are Tech Africa du 30 octobre.
16) David Ehl et Gianna-Carina Grün (2020). Why mobile internet is so expensive in Africa, 3 novembre.
- Ecrire un commentaire
- Commenter


























